Collect Polyhedral Benchmarks
by Pankaj Kukreja
Introduction
My work in this GSOC is to collect polyhedral kernels for measuring performance benefits of Polly. Currently, Polly’s performance is measured on PolyBench benchmark which doesn’t have many kernels.
Although we have a lot of benchmarks written in C/C++, we cannot use all of them because Polly’s SCoP is limited. For example it cannot optimize a loop which have non affine array access (A[B[i]] or A[cos(alpha)]) ,non affine loop bound, function calls etc.
I have used google benchmark library on the Image Processing kernels. Benchmark library measures the performance of the kernels by running multiple iterations of the kernel.
The function that executes the code to be measured is registered using the “BENCHMARK” macro. We can pass the parameter to the function using the “Arg” method. Benchmark library measures the runtime of code inside for(auto _ : state) and while(state.KeepRunning()) loops. Although the benchmark library runs the kernel for multiple inputs, we do not verify the output for each run as it will add a lot of overhead. We instead run the kernel for a single input in the main function and verify the output of this call.
Example of code using benchmark library
void BENCHMARK_BOX_BLUR(benchmark::State &state) {
int height = state.range(0);
int width = state.range(0);
int *outputImage = (int *)malloc(sizeof(int) * (height) * (width));
if (outputImage == NULL) {
std::cerr << "Insufficient memory\n";
exit(1);
}
boxBlurKernel(height, width, inputImage, outputImage);
while(state.KeepRunning()) {
boxBlurKernel(height, width, inputImage, outputImage);
}
free(outputImage);
}
BENCHMARK(BENCHMARK_BOX_BLUR)
->Arg(128)
->Arg(256)
->Arg(512)
->Arg(1024)
->Unit(benchmark::kMicrosecond);
Sample Output:
| Benchmark | Time | CPU | Iterations |
|---|---|---|---|
| BENCHMARK_BOX_BLUR/128 | 150 us | 150 us | 4662 |
| BENCHMARK_BOX_BLUR/256 | 626 us | 626 us | 1118 |
| BENCHMARK_BOX_BLUR/512 | 2321 us | 2321 us | 271 |
| BENCHMARK_BOX_BLUR/1024 | 9383 us | 9380 us | 75 |
My contributions:
I have added the following kernels in the test suite.
Image Processing Kernels
Anisotropic Diffusion
D49948
Anisotropic diffusion is a technique aiming at reducing image noise without removing significant parts of the image content, typically edges, lines or other details that are important for the interpretation of the image.
Bilateral Filter
D50529
Bilateral filter is a non-linear, edge-preserving, and noise-reducing smoothing filter for images. It replaces the intensity of each pixel with a weighted average of intensity values from nearby pixels. This weight can be based on a Gaussian distribution.
Dilate
D49883
For grayscale images, dilation increases the brightness of objects by taking the neighborhood maximum when passing the structuring element over the image.
Dither
D49503
Dither is an intentionally applied form of noise used to randomize quantization error, preventing large-scale patterns such as color banding in images. A common use of dither is converting a grayscale image to black and white, such that the density of black dots in the new image approximates the average grey level in the original.
In the patch, Ordered dithering and Floyd Steinberg dithering algorithms are implemented.
Ordered dithering: The algorithm achieves dithering by applying a threshold map M on the pixels displayed, causing some of the pixels to be rendered at a different color, depending on how far in between the color is of available color entries.
Floyd Steinberg dithering: The algorithm achieves dithering using error diffusion, meaning it adds the residual quantization error of a pixel onto its neighboring pixels, to be dealt with later.
Harris Corner Detector
D47675
Harris Corner Detector is a corner detection operator that is commonly used in computer vision algorithms to extract corners and infer features of an image.
Interpolation
D50345
Interpolation is a method of constructing new data points within the range of a discrete set of known data points.
In the patch, Bilinear and Bicubic Image interpolation algorithms are implemented.
Bilinear: It performs linear interpolation first in one direction, and then again in the other direction. Although each step is linear in the sampled values and in the position, the interpolation as a whole is not linear but rather quadratic in the sample location.
Bicubic: Bicubic interpolation is an extension of cubic interpolation for interpolating data points on a two-dimensional regular grid.
Blur
D49341
Box Blur: A box blur (also known as a box linear filter) is a spatial domain linear filter in which each pixel in the resulting image has a value equal to the average value of its neighboring pixels in the input image.
Gaussian Blur: In Gaussian Blur operation, the image is convolved with a Gaussian filter. The filter is made using the Gaussian function.
Rodinia Benchmark
Rodinia Benchmark Suite is a collection of parallel programs which targets heterogeneous computing platforms with both multicore CPUs and GPUs. Polly detects SCoPs in the following Rodinia benchmark’s kernels:
Backprop
D48046
Backpropagation is a machine-learning algorithm that trains the weights of connecting nodes on a layered neural network. The application is comprised of two phases: the Forward Phase, in which the activations are propagated from the input to the output layer, and the Backward Phase, in which the error between the observed and requested values in the output layer is propagated backward to adjust the weights and bias values.
Pathfinder
D49886
PathFinder is a dynamic programming algorithm to find the shortest path of a 2D grid, row by row, by choosing the smallest accumulated weights
Hotspot
D49894
HotSpot is a thermal simulation tool used for estimating processor temperature based on an architectural floor plan and simulated power measurements.
Srad
D49891
SRAD is a diffusion algorithm based on partial differential equations and used for removing the speckles in an image without sacrificing important image features. SRAD is widely used in ultrasonic and radar imaging applications.
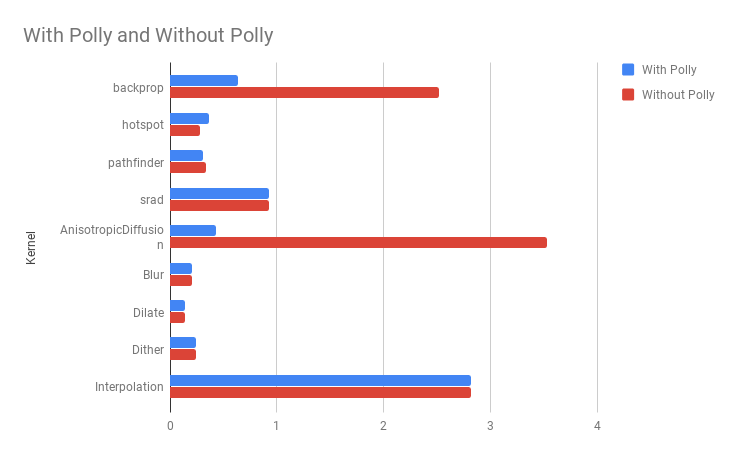
Runtime comparison
Following graph shows the runtime comparison when kernels are compiled with and without Polly.
Other work
Apart from kernels mentioned above, I have also tried making changes to some kernels of the following benchmarks so that Polly could optimize them.
- Other Image Processing Kernels
- Histogram of gradients
- Oil Filter
- Crater texture
- Rotate
- Quild Effect
- etc
- Remaining Rodinia benchmark kernels
- b+tree
- leukocyte
- particlefilter
- CFD
- etc
- SPEC OMP 2012
- Machsuite
Future Work:
There are lots of benchmarks written in C/C++ which are yet to be checked/modified for Polly. The future work would be to find as many benchmarks as possible which are recognized by Polly and add them to the test suite. It can be either some kernel from physics (like computation in fluid dynamics), data mining (like betweenness centrality) or any other domain.