Enable Polyhedral Optimizations in XLA through LLVM/Polly
by Annanay Agarwal
The problem statement
My project was to incorporate polyhedral compilation into TensorFlow, the deep learning framework by Google.
The proposed solution
Integrate Polly (the polyhedral loop optimizer in LLVM) into the LLVM framework used in TensorFlow through their JIT compiler - XLA that uses LLVM as a backend.
Steps taken
- XLA is built using the Bazel build system (which is Google’s alternate to Make). To build Polly using the Bazel framework, I had to learn the Bazel build scripting language and implement the build config files for Polly (and its dependencies like ISL) in Bazel.
- Once a clean build for Polly enabled LLVM was obtained in XLA, the compiled Polly files had to be linked (static / dynamic) to the XLA runtime. The static linking approach was used and the rule was added in the Bazel configuration. The Bazel build files can now be found at this link.
- Next, Polly’s passes had to be initialized and added to LLVM’s PassManager in XLA. The changed files can be found here.
- Polly works by recognizing the most compute intensive regions of a program - deeply nested loops - and transforming them into the most suitable schedule for maximum speedups. These regions of a program which have loops with affine accesses (statements inside the loop are an affine function of loop parameters) are called Static Control Parts or SCoPs. Once Polly’s passes were initialized in the XLA pipeline, the next task was to check if these SCoPs were sufficiently recognized and optimized by Polly’s passes.
- To check for optimal SCoP detection, a series of programs were run through the JIT compiler and their IR dumps from the JIT compiler were analyzed. The TensorFlow compiler is multithreaded, and would print corrupted IR in the dump. It was made single threaded for stdout safety.
- TensorFlow is a library that works on computation graphs. It creates nodes that work as operations like in an Abstract Syntax Tree. For JIT compilation through XLA, TensorFlow offloads specific subgraphs of computation to XLA, these subgraphs are then JIT compiled through XLA. Every time a particular Python program was run, multiple LLVM IR dumps were obtained which corresponded to the multiple subgraphs offloaded to XLA for JIT compilation. Out of these, it was a task to isolate the subgraph of a particular operation that we wanted to compile into LLVM IR.
- Next, the problem encountered was of passing configuration flags to TensorFlow for LLVM runtime configuration. Although the API kept changing, the initial way to do this was figured out to be by passing
TF_FLAGS="xla_cpu_llvm_cl_opts"along the Python command. TensorFlow relies on an external library - Eigen - for fast implementations of Convolution and other operators. These Eigen implementations had to be disabled in order to get the TensorFlow compiler to pass these to the JIT compiler. - Once the required LLVM IR for the operation under consideration was obtained, the next task was to figure out if Polly was able to detect SCoPs in the IR, optimize them and generate efficient code. This was an iterative mechanism and some of Polly’s optimization passes were altered and improved in the process.
- The LLVM IR generated by TensorFlow had certain characteristics, one such characteristic was that when encountered with a bound check on an array, the LLVM IR code-generator would optimize out one comparison operator. Ex: To check for
0 < i < 64, the code-generator would generate code that checked(unsigned)i < 64. Polly did not have the mechanism in place to handle unsigned comparisons. Support for unsigned comparisons was thus added in Polly and the relevant PR is here. - After these changes were made to Polly’s SCoP detector, the SCoPs detected for convolution are as follows:
- A general analysis tells us that a number of operations in deep learning frameworks actually boil down to the matrix multiplication operation. Hence, a number of programs with operations having a heavy use of matrix multiplication operation were run, and their generated IR analyzed. It was found that Polly was not able to optimize some of the matrix multiplication operations due to constraints on internal representations used by its Integer Set Library (ISL). These constraints were relaxed in this PR.
- To “necessarily” compile a piece of Python code using JIT, the following code can be used.
jit_scope = tf.contrib.compiler.jit.experimental_jit_scope with jit_scope(): # Code that should be JIT'ted
Current status of work
Polly has successfully been integrated into TensorFlow, and the official upstreaming is underway. The PR can be found here. Work is underway to make Polly an optional pass in the TensorFlow pipeline as seen in the discussions. I am also planning to work on another Convolution optimization - Convolution can essentially reduced to matrix multiplication, the difference being that in conventional Matmul both matrices are of comparable dimensions, whereas here one matrix (the filter) is usually much smaller than the other (the image). Hence, the filter matrix can always be stored in main memory as opposed to conventional matmul.
Result and benchmarks
Tests were run on a machine with the following stats:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 24
On-line CPU(s) list: 0-23
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 44
Stepping: 2
CPU MHz: 1600.000
BogoMIPS: 6131.56
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 12288K
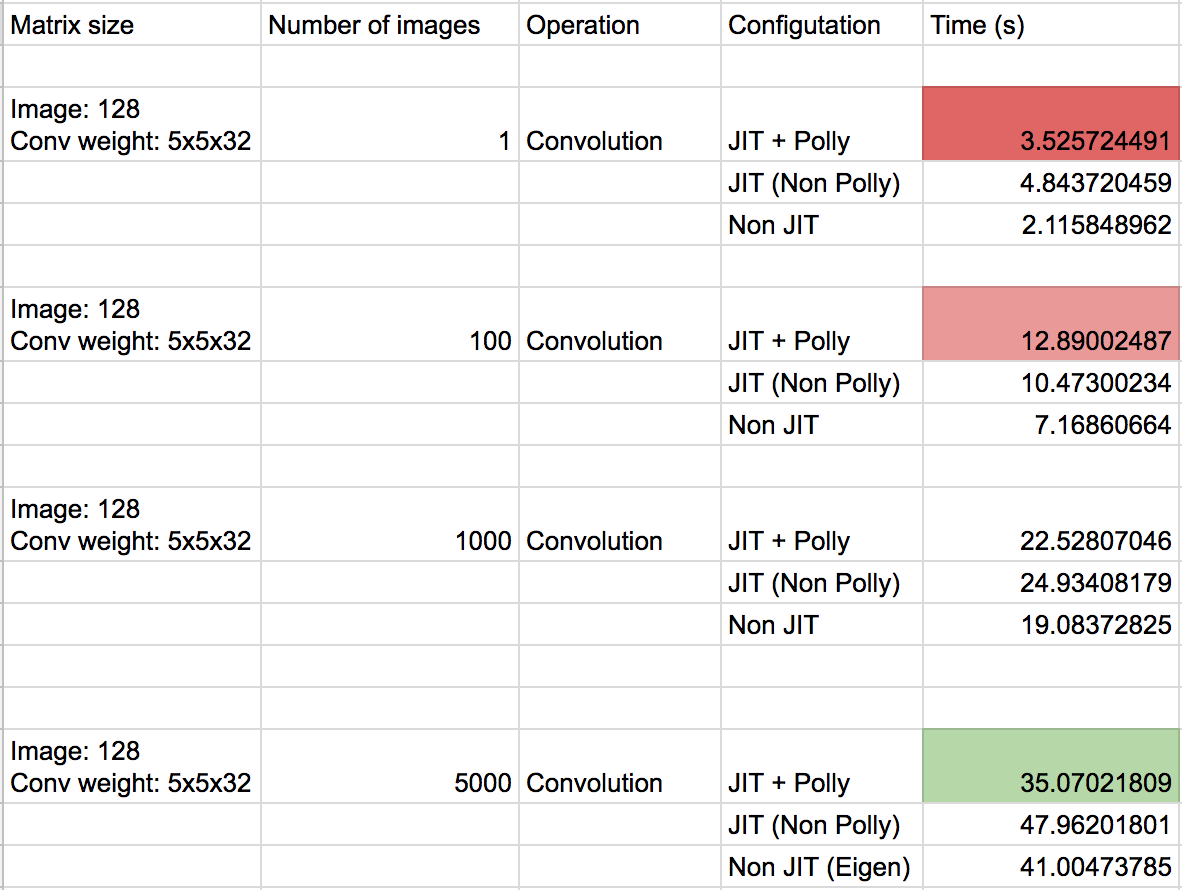
Convolution
The convolution operator was applied on a number of images as in this pseudo code.
# Do the process for N images
for i in range(N)
# pick a random image from the set of images
img = mnist.train.next_batch(batch_size)
# apply the convolution operation with a 5x5 weight - 32 such filters
conv = tf.conv2d(img, filter)
The three numbers show Non-JIT version (Eigen implementations), JIT without Polly and JIT with Polly.
Matrix multiplication
Due to some last minute benchmarking issues, this could not be benchmarked.
Why is Polly performance better?
With an exact dependence analysis and a good scheduling algorithm, Polly is better capable of optimizing the loops in the program over regular LLVM optimization passes. This is the result of polyhedral analysis passes which model the iteration space as points on polyhedra in N dimension space (where N is the depth of the loop). Dependency analysis and transformations are then performed with the help of a thread safe Integer Set Library (ISL) and an optimal schedule for running the program is thus derived.
Polly also has a specific optimization for the matrix multiplication operation. This enables special tiling and other data locality optimizations to improve the performance of matrix multiplication manifold.
Scope of improvement
Polly as an optimization pass in TensorFlow is a work in progress. When an complete pass of Convolution + Bias Addition + Softmax is passed through the JIT compiler, Polly is unable to fuse some operations into one loop (which is theoretically possible). This requires refactoring both on the Polly side as well as the TensorFlow side. On the TensorFlow side, XLA (and hence Polly) should have a broader spectrum and should be allowed to handle entire graphs instead of subgraphs that are passed to it to be optimized. Polly’s scheduling algorithm would work better if given a large piece of code to optimize rather than to run the scheduling algorithm (costly) multiple times on some chunks of the program. On the Polly side, there are some scalability issues wherein Polly bails out while handling of large SCoPs. This would typically be the scenario when a complete pass or with a complex neural network like RNN is passed through Polly’s SCoP detection. Compilation time significantly goes up as we add Polly’s passes in the pipeline, and this may be a concern for some applications written in Python for which compilation time might be important. However, improvements in execution time overcast the increase in compilation time.
Polly’s passes for SCoP detection are also expensive in terms of memory usage at the time of compilation since loading information of a large SCoP like that of an RNN. Below is an image of the memory usage on my local machine.
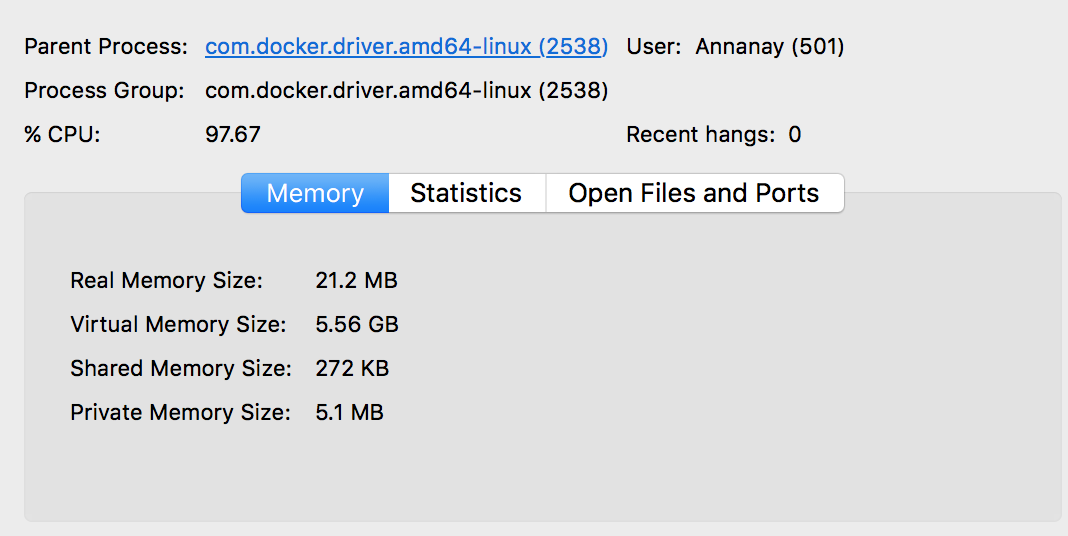 It is quite clear that these numbers could blow up if a complete pass was added to the neural network pipeline.
It is quite clear that these numbers could blow up if a complete pass was added to the neural network pipeline.
All this aside, the potential of Polly in bringing speedups to training programs is now obvious. Benchmarks of neural networks training run up to days and Polly’s transformations can have a huge impact on such programs, reducing the execution time to a fraction.
Future work
The TensorFlow runtime relies on a cost model to decide which parts of the program should be JIT compiled. This cost modeling should be left to Polly which is capable of generating GPGPU code. It would be really useful to have Polly as a Backend in TensorFlow. This would take away a lot of responsibility of scheduling from the JIT compiler (XLA) since the mechanism and framework is already implemented in Polly.